Walking down memory lane (part 3)
If you remember our previous part 2 article we used a central memory location to share data between two separate threads each running either in the same process or across separate processes. These processes could even be located on separate machine or even be written in two different languages.
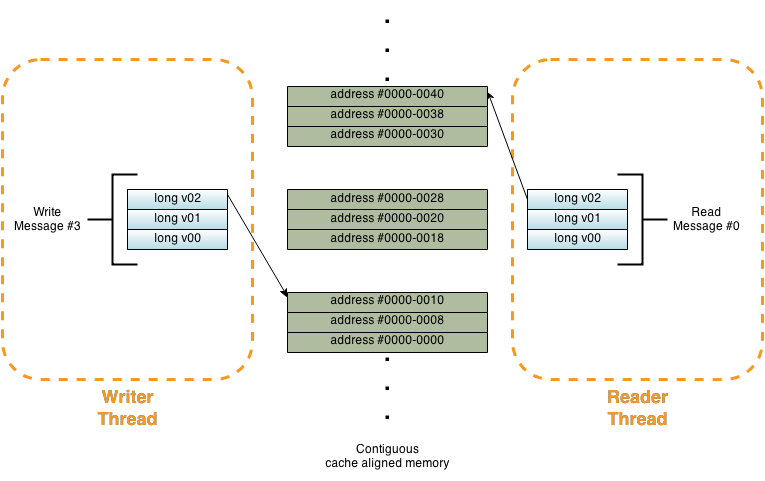
From the above you can see that we only have one thread writing to the shared data. The other thread is only reading this shared data once it is notified that the data was correctly published by the writer thread. Now the question is how do these threads synchronize access to this shared memory location with minimal contention ?
Lock free rings to the rescue
If we need to access this data concurrently we need to let the two separate threads agree (more like synchronize) access based on a locking mechanism. The trick here is to piggy back on the memory model provided by the processor. The cache coherency on x86 systems provides a happens-before guaranty when the data in a certain memory location is modified. However, if the memory is written using the Single Writer Principle that data is not propagated forcibly each time a write occurs to invalidate other caches. This basically means that, If the publishing thread writes to this memory location the other thread(s)/core(s) will see this change at some time in the future (and anything that happened before it) without impeding or affecting the publishing thread. As such, the publishing thread can keep updating that location. For the gory details i will point you to this article on CPU Cache and this one on memory barriers and fences.
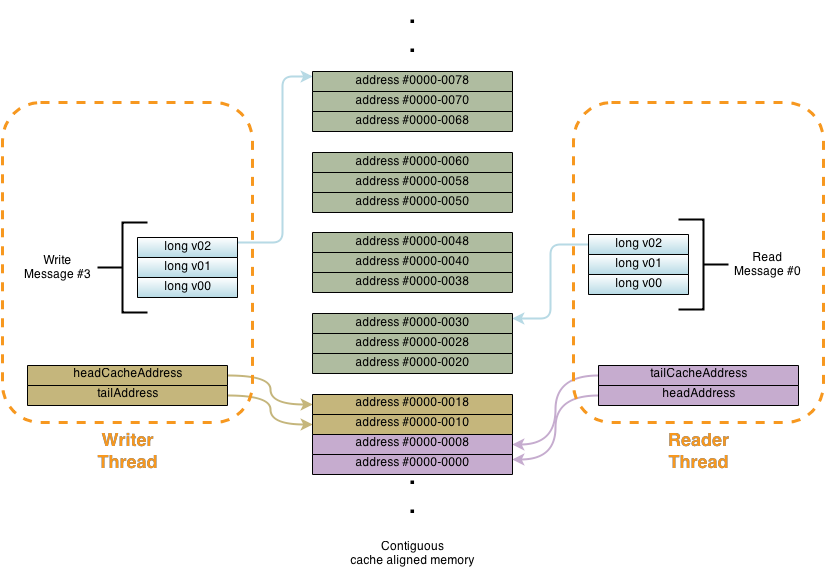
As can be seen above the two threads behaviour looks, conceptually, like a reservoir with one thread filling it from the top while the other thread is draining it. The memory is treated as a single contiguous stream of data with each message having a unique incrementally sequential location. The reader thread knows that the messages coming down the pipe have the same size and are all numbered in a sequential manner and keeps track of the last message position that was fetched from the pipe (head). On the other hand, the publishing thread also knows the sequence number of the last message written to the pipe (tail). Both sequences are augmented incrementally and independently via lock free based mechanism. The algorithm for inserting new elements in this queue must enforce a limit since we only have a very finite space for storing things. Ergo the notion of a circular ring buffer. The writer thread needs to make sure no new elements are inserted when the circular ring buffer is full. On a similar note, the reader thread also makes sure that if there are no new elements added since the last fetch it can spin lock waiting for new elements to be inserted. This algorithm is said to be lock free but not necessarily wait free. Meaning that we can bail out and go do other things when the queue is full/empty , making thus the algorithm practically wait free, or if there is nothing else to do we can do a spin lock until the situation is resolved. Meaning we lose the wait free portion but we are still lock free. From a pendantic point of view an algorithm is called lock free when progress is guaranteed for the system as a whole but not necessarily for each thread.
One can easily imagine how this buffer can be seen by multiple reader threads with one single publisher making broadcast or parallel type messaging. It is only a matter of adding more head/tail addresses and managing that accordingly when we are adding/removing items in the queue. Once the messages are read by multiple consumer threads they can all act on the same data in a parallel fashion or each consumer thread can be responsible for only part of the sequences based on a partitioning scheme. One particular partitioning technique championed by the Disruptor is to use a modulo for each reader so that for example odd sequence messages are handled by one reader while the others are handled by another reader. But we still get the same benefits in that the actual data will be paged by the kernel and available right away without incurring unnecessary cache misses. Once a block of data is written to memory we could use something like transferTo to finally achieve a zero copy like network transfer in Java while the publishing thread continues to write new data on a new location. the fact remains that each particular reader thread is effectively free to do what it pleases with the block of data without waiting or synchronizing with other threads.
Furthermore, as we said before, the consumer thread can be anything that can access this memory locations sequentially. This scheme can be used to not only communicate with lower level c/c++ code (or any code written in any language for that matter) but it can also be used to send data directly to GPUs running on the same machine. Once a sufficient amount of data is written by the thread publishing this block of data it can be copied over using DMA over the graphic processing card for example. The same obviously goes for sending/receiving data over high speed NIC cards or proprietary high speed transports.
Lets share some data !
I uploaded the code for this article on github. The application is using shared memory mapped files for the memory location. When i run the publisher and subscriber for a 50Million 8 byte (long) one way message stream (from publisher to subscriber only) on a AWS m3.2xlarge instance i am consistently getting ~140 Million messages per second. The test is repeated for 30times and averaged. On my AMD 4 core laptop i am getting a mere 13M messages per second. This is before we start talking about thread affinity and cpu isolation. If you can run this code on your own hardware give me a shout!